
Hey everyone, Neil here. Today I am going to be explaining how you can get hundreds or even thousands of free articles for your website but here is the catch, it is time sensitive and you must act now or they will be lost forever.
Okay, let me explain what is going on.
Voices.Yahoo is as you may or may not have heard shut down. What started out as Associated Content was moved over to Yahoo! Voices in 2011 which was a place for writers to sell their “quality” content. This place for content quickly grew to hundreds of thousands of articles which are now in the Google Cache.
The articles will not stay in the Google Cache forever and soon they will be unique content hypothetically and ready to post on your own website. Can you imagine what 1,000 unique articles will do to your website? I guess this is not truly unlimited, but with over 2 million articles on Voices, there is room for everyone to get a piece of this content pie.
Let’s get started!
What You Will Learn
- How to scrape Voices.Yahoo Links
- How to ammend the list to Google Cache
- Download all the articles
What You Will Need
- Scrapebox
- Proxies (BuyProxies)
- Excel (or OpenOffice)
- Text Mechanic
- Web Downloader (Shared at the bottom of this page)
- CopyScape
Free Content Method
Step 1: The first thing that you want to do is fire up Scrapebox and input site:voices.yahoo.com as your custom footprint. This means you are going to scrape results based on anything on voices.yahoo with your keywords that is still indexed and in the Google Cache. If you click on any of these links in the SERPs since the site has been removed, they all redirect you to the home page. When they are recrawled, the content will be gone from the cache and should be unique if it has not been syndicated to other sites before.
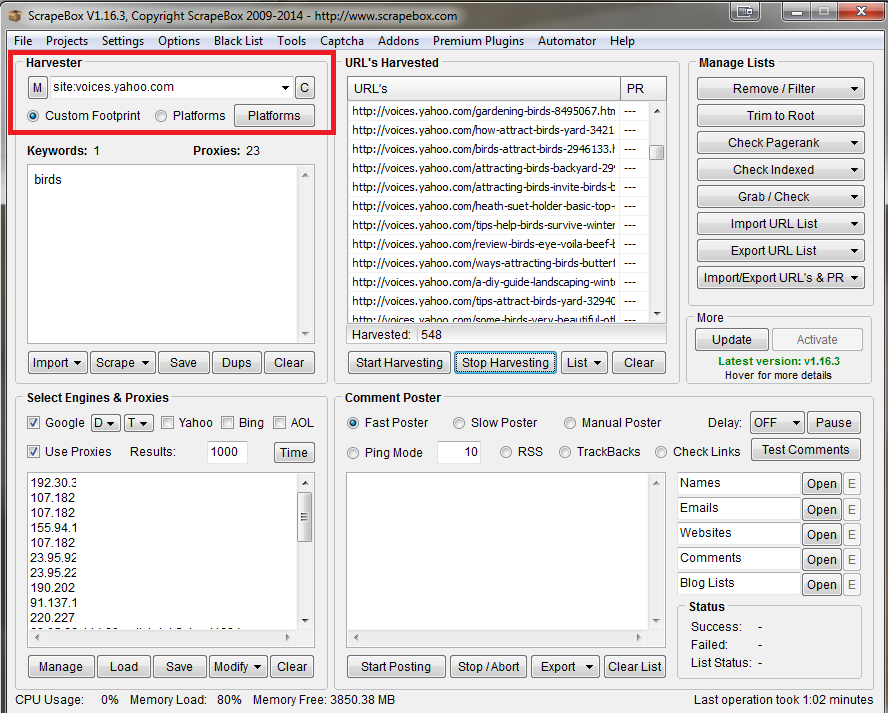
Step 2: Insert your keywords into the keyword box and load up some proxies to Scrapebox. I went out and bought 20 just for this method from BuyProxies and was relieved when they were activated 5 minutes later so I could start.
Step 3: Click on the Start Harvesting button after you have checked your proxies and made sure they are working. Depending on how many results are left int he SERPs this can be extremely quick, or take a while. Either way, sit back and wait for the links to start rolling in.
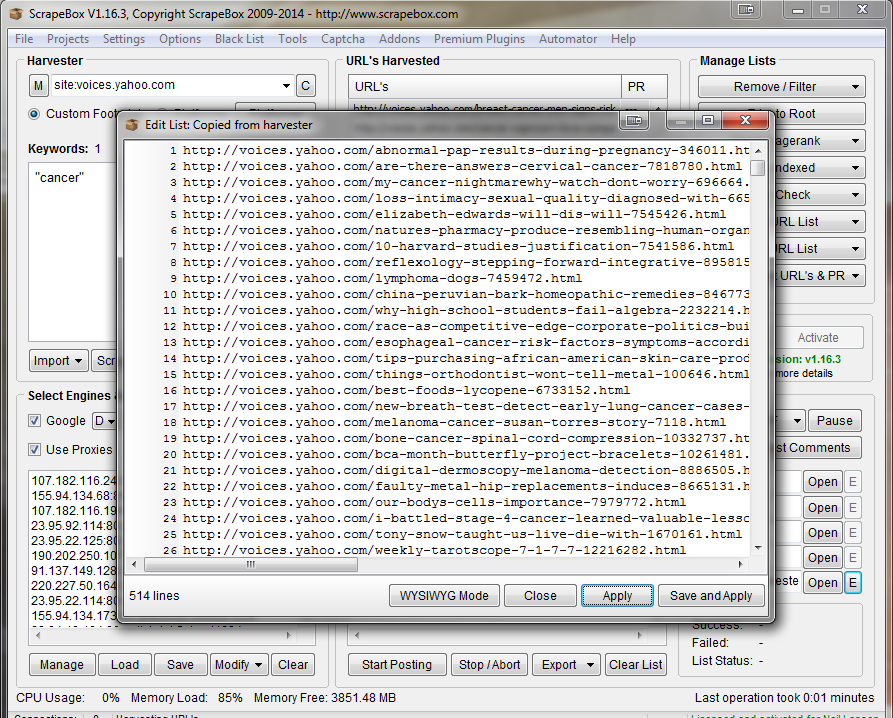
As you can see here, the links are all still http links and not Google cache links so we will need to chop them up a bit. You may also notice I changed my keyword, this was just to get better results.
Step 4: Copy all the links that was harvested and open up Excel or a similar program. You want to post all the links you just got into colum B. In Collum A, you will want to add http://webcache.googleusercontent.com/search?q=cache:. Make sure you do not include the period after the colon though.
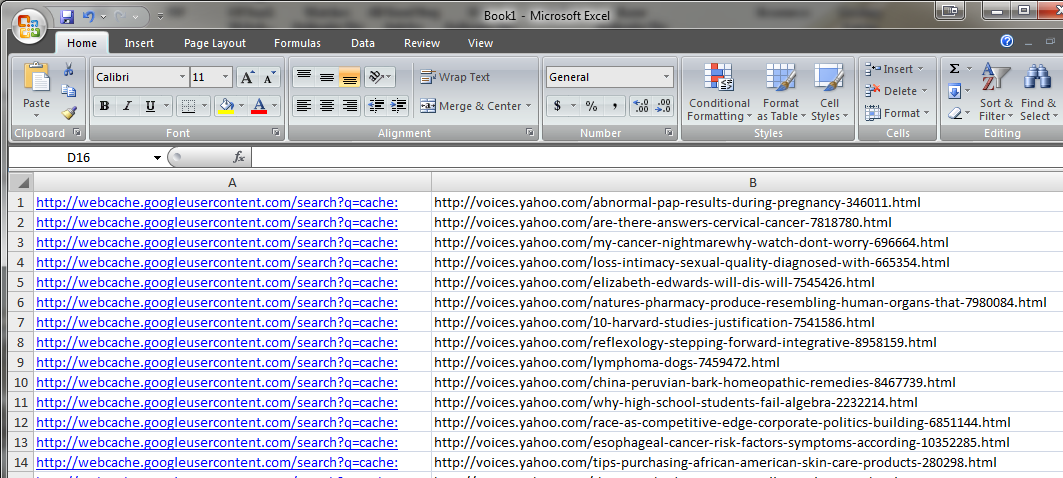
Step 5: We still need to get these 2 lines together and remove all spaces. There is probably a much faster way to do this but at 4 in the morning, this is the best sollution I could think of. First hit Control + F to bring up Find and Replace. Find all http:// and then replace them ALL with nothing. I could not get the links to work if http:// was included so I simply removed them all. After you have done this, copy your entire list from excel and head over to Text Mechanic. You want to select the option to remove all spaces.
- Uncheck the checkbox that says “Trim leading/trailing whitespaces from lines.
- Click Remove all spaces
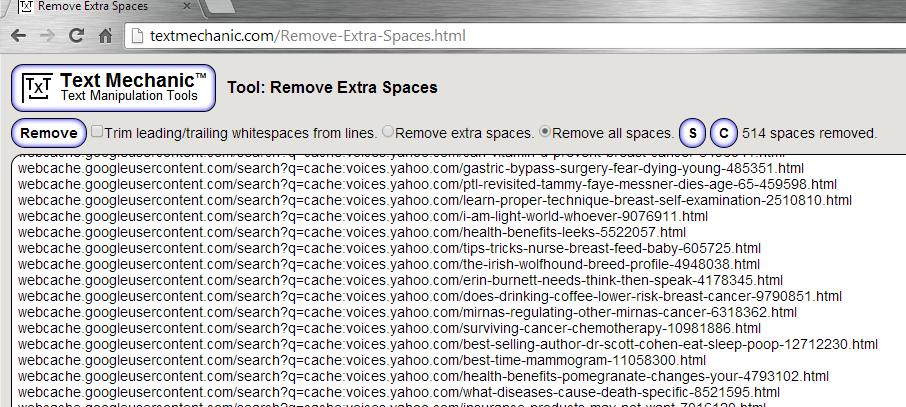
Step 6: Paste all these new lines into a text file. We are going to run them through the addon Scrapebox Alive Checker to see which ones are still available for us to pull down from the internet. When you have run your current list, save the alive URLs to a text file. This is what we will use to download the pages/articles.
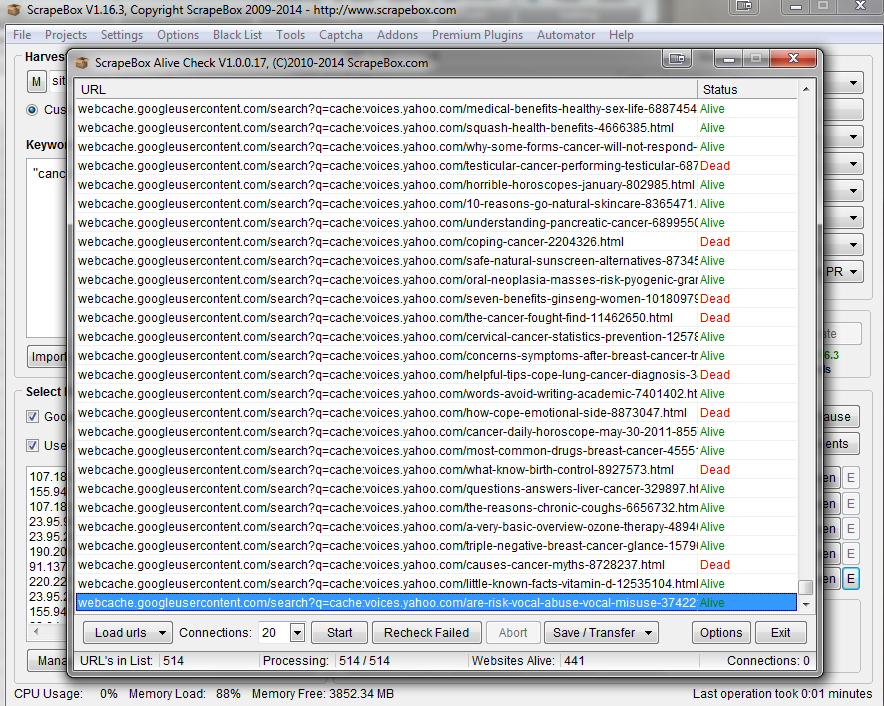
Step 7: Now you need to download the articles or web pages. This can be done with any type or http downloader. The only issue you may run into is that after 50 or so articles, Google will ban your IP. The way around this that I have found is to simply download a free VPN and switch your IP each time a proxy is thrown. I also am using Fatboy’s bot that he made in 20 min over at blackhatworld that you can get below.
Step 8: The last and final step is simply to wait until all the content is gone. Once this happens all you need to do is use copyscape or a similar program to check if the content is unique and has not been posted around the internet to scrape sites. If it turns out the content is unique, post it on your site and enjoy not paying anyone for all those free articles!
Obviously there are going to be some niches out there where the content has been pasted and rewritten a thousand times since some of these articles are coming from 2007, 2008, 2009 ect. However, there are many niches that I found where the only duplicate content that copyscape found was on voices.yahoo which is GONE. I plan to hold a case study in the future with some of this content to let you all know how it is working out.
That is all for now, let me know in the comments if you guys (and girls) were able to get some free articles using this method.
As always, if you liked this post and/or want other methods emailed to you when posted, feel free to subscribe.

Neil does it still work? I’m thirsty for free unique contents because
don’t have any money to outsource them.
No it does not, this was a one time off thing. Sorry! You should probably start writing yourself. It is the only way to get better!
That is very sorry for me.
I want to create so many niche sites(probably over hundreds sites) but don’t have any expertise for targetted niches so I’ve considered how to get unique quality contents that aren’t spent money if possible.
Have you created many sites(or blogs) to generate passive incomes? If that can you post how to do it?